
XPath, veri girişi ve analizi sırasında kolaylık sağlaması açısından öğrenmek zorunda kaldığım; öğrendikten sonra da iyi ki öğrenmişim dediğim bir dosya yolu sorgulama dilidir. Tabii ki kullanımı bununla sınırlı değildir. Ancak bu yazımda sizlere özellikle SEO analizinde Google E-Tablolar ile birlikte nasıl kullanırsınız ondan bahsedeceğim. Birkaç Xpath sorgusu ve bu sorgular ile web sayfalarından öğeleri nasıl çekebileceğinizi öğreneceksiniz. Kodlama dillerine aşinalığı olan birinin hızlı bir şekilde öğreneceğine inanıyorum. Ama herkese hitap edebilmesi adına yazımı giriş seviyesinde tuttuğumu belirtmek isterim. Peki, XPath nedir?
XPath Nedir?
İngilizcede “data scraping” olarak geçen, Türkçede veri kazıma dediğimiz işlemlerde kullanabileceğimiz bir tür sorgu dili olduğunu söyleyebiliriz. Kısacası, bir XML dosyasının spesifik yerlerinde yönümüzü bulmamızı sağlayan bir standarttır. Hatta tek bir XPath sorgusu ve tercih edeceğimiz veri kazıcısı ile onlarca sayfadan tek seferde veri çekebiliriz. Bununla birlikte içinden çıkılamaz kopyala yapıştır döngüsüne de girmemekteyiz.
İlk bakışta komplike görünebilir ama sizi korkutmasına izin vermeyin. Biraz pratik yaptıktan sonra aslında gayet basit bir mantığa sahip olduğunu göreceksiniz.
Xpath Kopya Kağıdı
Google E-tablolar ile nasıl veri çekebileceğinizi göstermeden önce sizlere bazı XPath sorguları vereceğim. Üstelik, bu sorguları istediğiniz herhangi bir web sayfası için kullanabilirsiniz. Kazımanın verileri çekmek anlamında kullanıldığını unutmayın!
| XPath Sorgusu | Çıktı |
|---|---|
| //h1 | Bütün h1'leri kazır. |
| //title | Bütün başlıkları kazır. |
| //meta[@name='description']/@content | Meta açıklamayı kazır. |
| //@href | Bütün linkleri kazır. |
| //link[@rel=’canonical’]/@href | Bütün canonicalları kazır. |
| //*[@itemtype]/@itemtype | Schema türlerini kazır. |
| //*[@hreflang] | hreflang'i kazır. |
Google E-Tablolar ve XPath ile Veri Kazıma
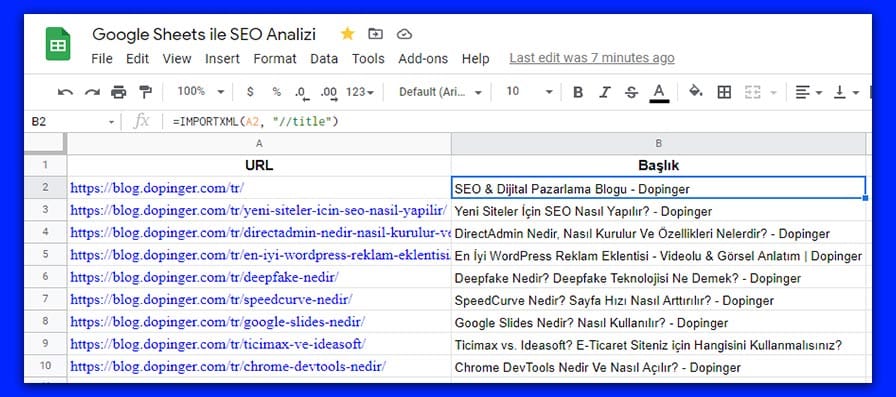
Alttaki görselde veri kazımak için kendi hazırladığım Google E-Tablo belgesini görebilirsiniz. A sütununa içinden veri çekmek istediğim URL’leri sıraladım.

B sütununa ise A sütunundaki her bir URL için kullanmak istediğimiz fonksiyonu yazacağız. Fonksiyonumuz şu şekildedir: =IMPORTXML
IMPORTXML iki parametre alır;
- URL: Veri çekmek istediğiniz URL ya da URL’yi içinde bulunduran hücrenin adı,
- XPath Sorgusu: Kullanmak istediğiniz XPath sorgusu.

Bu örnekteki fonksiyonumuz şu şekildedir;
=IMPORTXML(A2, “//title”)
Tırnak işaretlerine dikkat etmeyi unutmayın. Ayrıca XPath sorgusu yeşile döndüğünde doğru şekilde biçimlendirdiğinizi anlayacaksınız. Son olarak enter’a basın ve E-tablo otomatik olarak sayfanın başlığını çekecektir.
Takibinde A sütununa sıralı olarak başlığını çekmek istediğiniz başka URL’ler ekleyebilirsiniz. Tekrardan her bir URL için fonksiyon yazmanıza gerek yok. Tek yapmanız gereken formülün olduğunu hücreyi işaretleyerek sağ altındaki kareye çift tıklamaktır.

Tıpkı ilk adımda olduğu gibi Google E-Tablo otomatik olarak bütün URL’lerin başlıklarını çekecektir. Bu kadar basit!
ImportXML fonksiyonunu kullanmaya başlamadan önce eklemek istediğim son birkaç nokta var.
- Elinizde çok fazla sayıda URL yok ise kullanmalısınız.
- Bir E-Tablo sayfasında ImportXML’i 50 kereden fazla kullandığınızda çözülemeyen “yükleniyor” hatası almaya başlıyorsunuz.
- Çekmeyi planladığınız verinin JavaScript ile modifiye edilmemiş olması lazım.
Ne yazık ki ImportXML bazen çalışmayabiliyor. Böyle durumlarda ScreamingFrog’un özel ekstraksiyon aracını kullanabilirsiniz. Bir sonraki yazımda ScreamingFrog ile nasıl kazıma yapabileceğinizi anlatacağım!
Işık Hızında XPath Nedir?
Data scraping, başka bir deyişle veri kazıma dediğimiz işlemlerde kullanabileceğimiz bir tür sorgu dilidir. XPath sorgunuzu isteğinize göre özelleştirmek için pek çok seçenek vardır. Kısaca değinirsek, fonksiyon eklemek, true/false operatörleri kullanmak ve özel semboller bunlara dahildir.
Umarım veri kazımak için XPath kullanmanın temellerini sizlere aktarabilmişimdir. Devam yazımlarımda XPath’i çok daha yakından ve detaylı bir bakış ile inceleyeceğiz. Son olarak, gerçek bir XPath ustası olmayı hedefliyorsanız blogumuzu takipte kalın!
Google e-tablolar ile kırık link kontrolü yapmayı öğrenmek için diğer blog yazımızı okuyun!
SEO hakkında bilgi almak için: https://www.dopinger.com/tr/seo/
Hakkında Sıkça Sorulan Sorular
İngilizcede “data scraping” olarak geçen, Türkçede veri kazıma dediğimiz işlemlerde kullanabileceğimiz bir tür sorgu dilidir.
XPath sorgularını Google E-Tablolar veya ScreamingFrog üzerinde kullanarak SEO analizi yapmak için gerekli verilere ulaşabilirsiniz.
XPath’in avantajı verileri manuel olarak tek tek çekmek yerine otomatik bir şekilde kazıyabilmenizdir.




Gösterilecek yorum yok.